[Paper Review] NeRF: Neural Radiance Fields for View Synthesis(ECCV2020)
Information
Title: NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis(ECCV2020)
Source: https://www.matthewtancik.com/nerf
NeRF: Neural Radiance Fields
A method for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views.
www.matthewtancik.com
Abstract
- 저자는 지금의 방법(NeRF)을 제안하여 view synthesis 부분에서 state-of-the-art(SOAT)를 이루어냈다.
- 저자는 Input으로 5D-coordinate(x, y, z, θ, φ) 제안했다.
- 저자들이 5D-coordinate(x, y, z, θ, φ)를 제안한 이유는 location(x, y, z)만을 가지고 representation하는 것은 한계가 있어 제안을 했다고 한다.
1. Introduction

- 저자들은 Input으로 5D-coordinate(x, y, z, θ, φ)을 제안 했는데, 3D 좌표(x, y, z)와 바라보는 방향(θ, φ)을 통해서
Output으로 radiance(RGB)와 Density을 출력한다.
- 정지된 장면에 있어 여러장의 이미지를 넣어서 이전에 없던 Viewing Direction에서의 이미지를 출력한다.
- 해당 방법은 FCN을 통해서 Output을 출력하고 하나의 5D-coordinate으로 하나의 radiance(RGB)와 Density을 출력한다.
Summary
- MLP 네트워크로 Complex geometry과 materials를 표현하는 방식 제안
- 기존 미분가능한 classic rendering 방식을 기반으로 parameter 학습을 수행한다.
- 5D-coordinate을 더 고차원 공간에 mapping하는 positional encoding을 제안, 이를 통해서 높은 퀄리티의 representation 할 수 있었다.
2. Neural Radiance Field Scene Representation

Over View
- 하나의 camera ray의 5D-coordiantes(X, d)를 MLP 네트워크를 거쳐 c(RGB)와 σ(volume density)를 출력한다.
- 해당 rendering function은 미분이 가능하기 때문에 Prediction한 Pixel과 Ground Truth 사이에 loss로 Back Propagation(역전파)를 통해 최적화 할 수 있다.
- 여기서 c(RGB)는 모든 Input 5D에 의해 결정되지만, σ(volume density)는 오직 location(X)에 의해서 결정된다.
*해당 추가설명은 아래에서 할 예정
1. X만 가지고 8개의 fully-connectec layer를 통해 σ(volume density)와 256차원의 feature vector를 출력
2. 이후 feature vector와 cmaera's ray의 viewing direction이 합쳐져서 추가 fully-connected layer(128 channels)을 지나서 RGB값을 출력한다.
*여기서 모든 layer는 ReLU 활성함수를 사용한다.
위 과정을 통해서 시점마다 다르게 보이는 부분까지 나타내는 효과를 얻을 수 있다.
3. Volume Rendering with Radiance Fields
여기서는 Input을 통해서 색상 c(RGB)를 구하는데 classic volume Rendering 방식을 이용한 언급했는데 이에 대한 설명이 여기서 나옵니다.
- r(t) : Camera Ray
* r(t) = o + td (o: 카메라 위치 d: Ray 방향벡터 t: paramiter(샘플링되는 점이 달라진다.)) - T(t) : Transmittance(투과도) Density가 높을수록 weight가 작아진다.
- σ(r(t)) : 하나의 RAY(r(t))에 대해 Volume Density 값으로, 하나의 Location에 point들의 대한 값이다.
- c(r(t),d) : Location과 Direction을 통해 구해지는 Color 이다.



[그림 1] 식에서 의미가 Input(Location, Viewing Direction)와 T(t) 투과도에 의해서 한 Ray의 픽셀 RGB가 결정된다.
여기서 T(t)는 투과도의 의미로 한 Ray에서 t_n ~ t_f까지 particle의 Density의 누적 합을 의미하면 이전 값이 클 경우 weight가 작다. (즉 앞에 Density가 높아 가려지는 의미)
*T(t) 식을 살펴보면, accumulated transmittance로, t까지의 point들의 투명도를 나타내는 것 이다.
(δ_j가 같은 조건일때)
즉 T_i가 크다면 투과율이 높다는 것이고 weight가 적게 적용된다.(즉 σ(volume density)가 클때)
반대로 T_작다면 투과율이 낮다는 것이고 weight가 높게 적용된다.(즉 σ(volume density)가 작을 때)
[그림 2] 식에서는 한 Ray에 t_n부터 t_f까지 샘플링 되는 point들 대해 랜덤하게 샘플링을 한다.(매 train마다 다른 t_i값이 들어간다.)
이를 통해서 저자들이 얻고자 하는 것은 coninuous scene을 얻고자 하는 것이다.
[그림 3] 식은 rendering 분야에서 흔하게 사용한다고 언급하였다. (나중에 한번 찾아볼 예정)
δ_i = t_n부터 t_f 사이 sampling되는 point 간격(즉 t_i+1와 t_i 사이 값을 의), α_i= 1−exp(−σ_i x δ_i)
* 해당 과정이 Coarse Model이라고 하며, 아래에서 따로 설명을 진행합니다.
아래에서 Coarse Model과 Fine Model을 통해 성능을 개선한다고 합니다.
4. Optimizing a Neural Radiance Field
Positional encoding / Hierarchical sampling
- Positional encoding
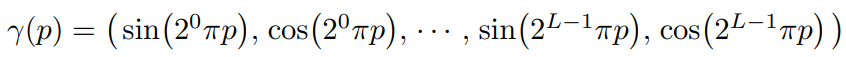

Deep Network는 low-frequency쪽으로 편향되어 학습되는 문제가 있다. 이를 해결하기 위해서 NeRF는
Positional encoding 과정으로 통해서 high-frequencey 영역까지 표현할 수 있도록 하였다.
5D-coordiantes를 통해서 복잡한 표현을 하기에 위해서 데이터를 늘리기 방식이라고 이해했다.
r(p)에 p로 이제 (x, y, z) 중에 대해 하나의 값을 넣어 좌표가 3개여서 Input r(x) 아래에 60이라 적혀있다.
그리고 중간에 한번더 posittional encoding이 들어가고 8번째 layer에서 σ(volume density)를 뽑아내고
viewing direction에 대한 posittional encoding이 적용된다.
(여기서 볼 수 있는 것이σ(volume density)는 location에 의해서 결정된다. )
* [그림 4] 식을 보면 (x, y, z)에 대해서는 60개 direction에 대해서는 24개가 세팅된 이유는 저자들이 실험을 할 때
해당 식에 있는 L 값을 L = 10 for r(x) L = 4 for r(d)로 세팅했다고 함.
때문에 Location에 대한 (x, y, z)는 20개씩 60차, direction에 대한 (x, y, z)는 개당 8개로 24차원가 나오게 됩니다.
*(direction(θ, φ)은 2개인데 L = 4 라면 왜 16개가 아닌 24개인가??)
- Hierarchical sampling


Rendering을 진행 할 때 학습을 반복하지 않았을 때, 결과물은 free space나 occluded regions 표현이 어려웠다.
해당 Hierarchical representation을 통해서 좋은 결과물을 얻기 위해 제안했다.
여기서 "coarse"와 "fine"에 대해 설명을 합니다.
첫번째 coarse Network를 통해서 sampling하여 N_c를 구합니다
그 후 샘플링 된 Density가 높은 부분에서 fine Network를 통해 한번더 샘플링을 하여 N_f를 구합니다.
위에 NeRF structure 사진에서 볼 수 있듯이 두개의 네트워크(coarse, fine)을 통해서 Loss를 계산합니다.
(Optimization iteration)
1. Random sampling camera ray
2. Hierarchical sampling N_c+N_f
3. volume rendering
4. computing Loss
Result

결과를 설명하면서 다른 method들과 비교하면서 NeRF가 꽃잎 뒤에 있는 물체들까지도 잘 표현을 해내고, Ghost 현상도 잡아내어 좋은 성능을 보인다고 합니다.
+개인적인 궁금증
- 저자들이 처음에 말하기를 반구형태로 다양한 camera ray를 사용한다 했는데 실제 결과물들은 대부분 일정범위 내에서 움직이는 것만 보여졌다. 그렇가면 완전 반대편에서의 이미지를 rendering한다면 어떤 결과물이 나오는지 궁금하다.
- 저자들이 원하기를 데이터 상 없는 view에서 이미지를 생성하고 싶다고 했는데 코드적으로 어떻게 돌아가는지 궁금하다.
*이후 실제 코드를 확인해볼 예정
- positional encoding 부분에서 viewing deirection(θ, φ)으로 Input이 들어가는데 L = 4 라면 24개가 아닌 16개이다.
찾아보니 viewing deirection에 대한 직각좌표계를 사용한다고 한다.
*(Direction의 x, y, z는 x, y 즉 카메라 위치에서 Ray의 방향를 z값으로 봅니다. )
그렇다면 이건 5D가 아닌 6D가 아닌가 라는 생각이 듭니다.
tmi)
처음으로 논문을 정리해보는 것인데 이렇게 하는게 맞는지 모르겠다....ㅎㅎ
일단 지금 관심이 있는 분야라서 그래도 흥미있게 읽을 수 있었다.
다음으로는 NeRF 후속 연구 중에서 학습시간 부분과 적은 data set으로 rendering에 대해 읽어 볼까 합니다.